概述:Unicode解码
参考文章:
前言
由于前后端交互中编码的问题,出现了这样的一串字符:
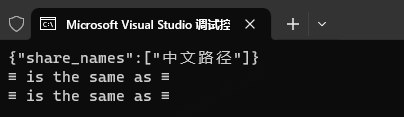
{"share_names":["\u4e2d\u6587\u8def\u5f84"]}出现了unicode编码作为字符串内容的情况,直接用json解析的话会报错,所以在json解析前需要先进行转码,两种方案
- 所有的 ASCII 编码转为 UNICODE
- 所有 UNICODE 转为 ASCII
常规思维就是 UNICODE 转为 ASCII。
思路
UNICODE 编码占用了两个字节,所以在处理时需要使用宽字符,也就是 wchar_t 或者 wstring。
特征:
UNICODE 的编码格式固定:\udddd 的形式。
步骤说明:
- 遍历整个字符串
- 发现
\\u则读取对应的dddd - 保存
dddd到宽字符串中。需要按照 16 进制读取。
代码
C++版本
string Unescape(const string& input) {
wstring wresult;
for (size_t i = 0; i < input.length(); ) {
if (input[i] == '\\' && input[i + 1] == 'u') {
string code = input.substr(i + 2, 4);
wchar_t unicode = stoi(code, nullptr, 16);
wresult += unicode;
i += 6;
} else {
wresult += input[i++];
}
}
wstring_convert<codecvt_utf8<wchar_t>> conv;
string result = conv.to_bytes(wresult);
return result;
}ATL版本
CString Unescape(const CString& csInput) {
string input = CW2A(csInput);
wstring wresult;
for (size_t i = 0; i < input.length(); ) {
if (input[i] == '\\' && input[i + 1] == 'u') {
string code = input.substr(i + 2, 4);
wchar_t unicode = stoi(code, nullptr, 16);
wresult += unicode;
i += 6;
}
else {
wresult += input[i++];
}
}
CString csResult;
csResult.Format(L"%s", wresult);
return csResult;
}补充
如果直接使用 C++ string 构造的话,就能正确识别十六进制中文字符
#include <iostream>
using namespace std;
int main() {
string jsonStr = "{\"share_names\":[\"\u4e2d\u6587\u8def\u5f84\"]}";
cout << jsonStr << endl;
cout << "≡ is the same as \u2261" << endl;
string s("≡ is the same as \u2261");
cout << s << endl;
}